What the gips is based on
The package is based on the article [1]. There the math behind the package is precisely demonstrated, and all the theorems are proven.
In this vignette, we present a gentle introduction. We want to point
out all the most important results from this work from the user’s point
of view. We will also show examples of those results in the
gips package.
As mentioned in the abstract, the outline of the paper is to “derive
the distribution of the maximum likelihood estimate of the covariance
parameter
(…)” and then to “perform Bayesian model selection in the class of
complete Gaussian models invariant by the action of a subgroup of the
symmetric group (…)”. Those ideas are implemented in the
gips package.
Basic definitions
Let be a finite index set, and for every , be a multivariate random variable following a centered Gaussian model , and let be an i.i.d. (independent and identically distributed) sample from this distribution. Name the whole sample .
Let denote the symmetric group on , that is, the set of all permutations on with function composition as the group operation. Let be an arbitrary subgroup of . The model is said to be invariant under the action of if for all , (here, we identify a permutation with its permutation matrix).
For a subgroup , we define the colored space, i.e., the space of symmetric matrices invariant under , and the colored cone of positive definite matrices valued in ,
Block Decomposition - [1], Theorem 1
The main theoretical result in this theory (Theorem 1 in [1]) states that given a permutation subgroup there exists an orthogonal matrix such that all the symmetric matrices can be transformed into block-diagonal form.
The exact form of blocks depends on so-called structure constants . It is worth noting that for cyclic groups . Because gips searches only within cyclic subgroups, this simplifies the theory.
Examples
p <- 6
S <- matrix(c(
1.1, 0.9, 0.8, 0.7, 0.8, 0.9,
0.9, 1.1, 0.9, 0.8, 0.7, 0.8,
0.8, 0.9, 1.1, 0.9, 0.8, 0.7,
0.7, 0.8, 0.9, 1.1, 0.9, 0.8,
0.8, 0.7, 0.8, 0.9, 1.1, 0.9,
0.9, 0.8, 0.7, 0.8, 0.9, 1.1
), nrow = p)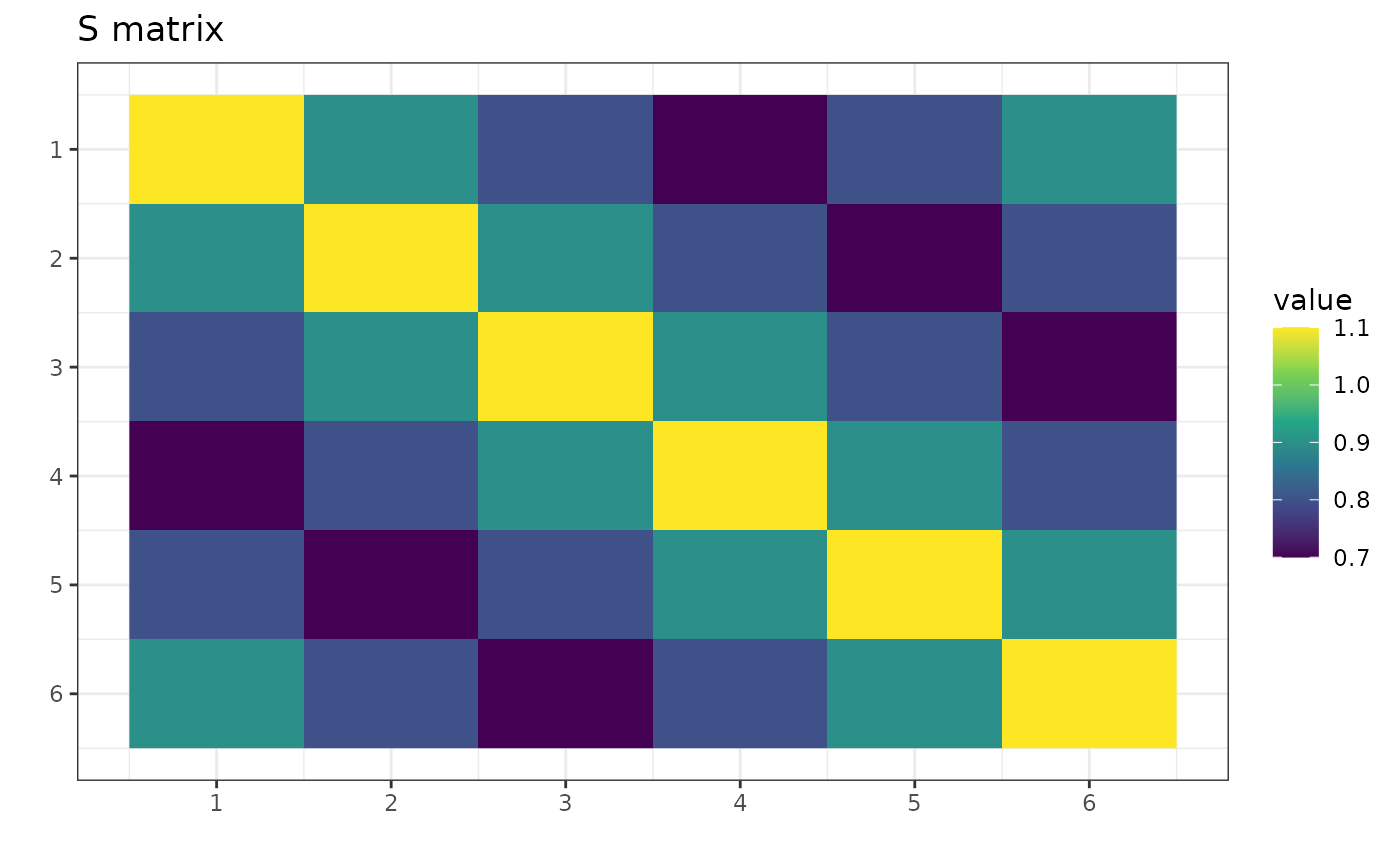
S is a symmetric matrix invariant under the group
.
g_perm <- gips_perm("(1,2,3,4,5,6)", p)
U_Gamma <- prepare_orthogonal_matrix(g_perm)
block_decomposition <- t(U_Gamma) %*% S %*% U_Gamma
round(block_decomposition, 5)
#> [,1] [,2] [,3] [,4] [,5] [,6]
#> [1,] 5.2 0.0 0.0 0.0 0.0 0.0
#> [2,] 0.0 0.5 0.0 0.0 0.0 0.0
#> [3,] 0.0 0.0 0.5 0.0 0.0 0.0
#> [4,] 0.0 0.0 0.0 0.1 0.0 0.0
#> [5,] 0.0 0.0 0.0 0.0 0.1 0.0
#> [6,] 0.0 0.0 0.0 0.0 0.0 0.2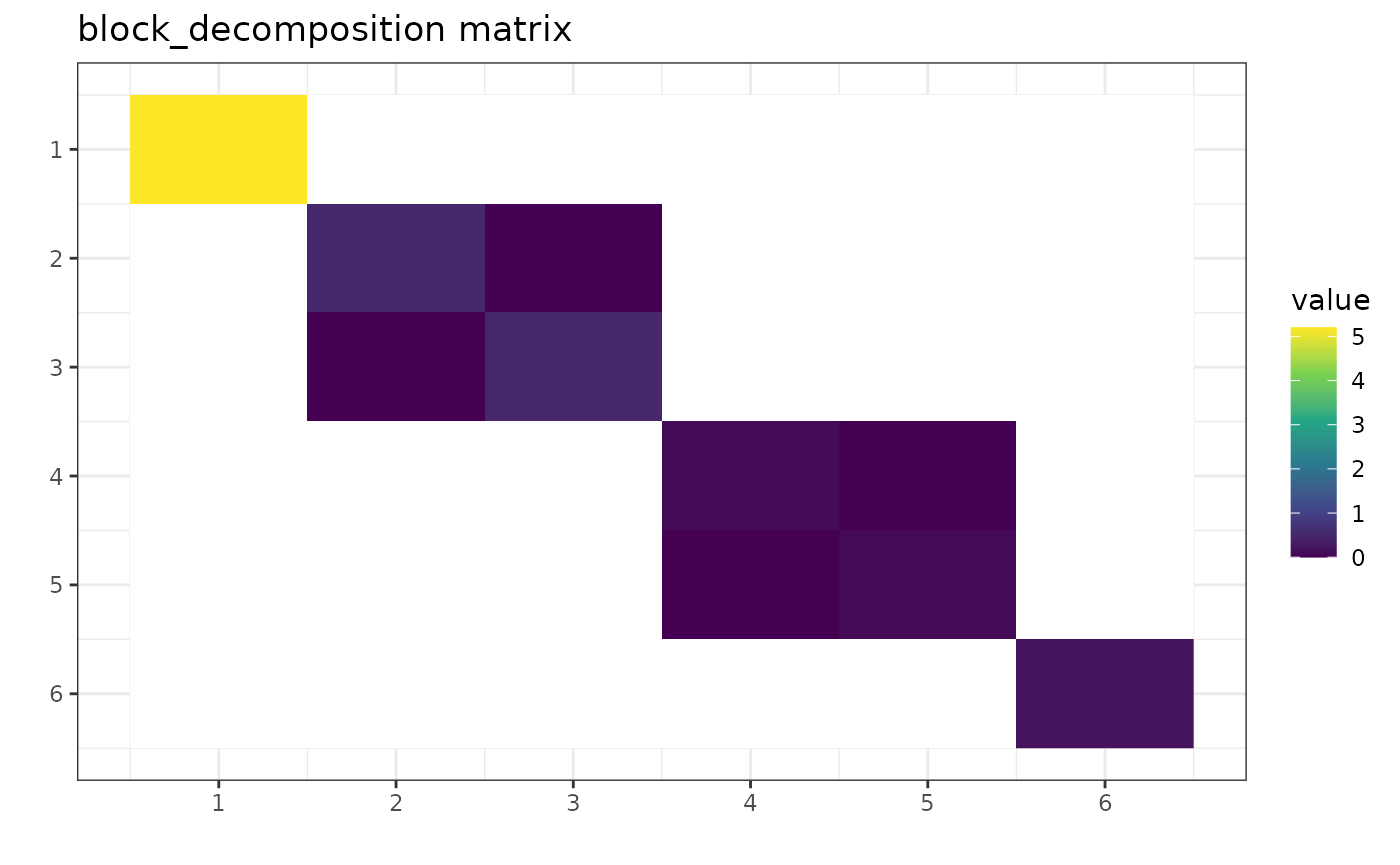
The transformed matrix is in the block-diagonal form of [1], Theorem 1. Blank entries are off-block entries and equal to 0. Notice that, for example, position [2,3] is not blank even though its value is 0. This is because it is a part of the block-diagonal form but happens to have a value of 0.
The result was rounded to the 5th place after the decimal to hide the inaccuracies of floating point arithmetic.
Let’s see the other example:
p <- 6
S <- matrix(c(
1.2, 0.9, 0.9, 0.4, 0.2, 0.1,
0.9, 1.2, 0.9, 0.1, 0.4, 0.2,
0.9, 0.9, 1.2, 0.2, 0.1, 0.4,
0.4, 0.1, 0.2, 1.2, 0.9, 0.9,
0.2, 0.4, 0.1, 0.9, 1.2, 0.9,
0.1, 0.2, 0.4, 0.9, 0.9, 1.2
), nrow = p)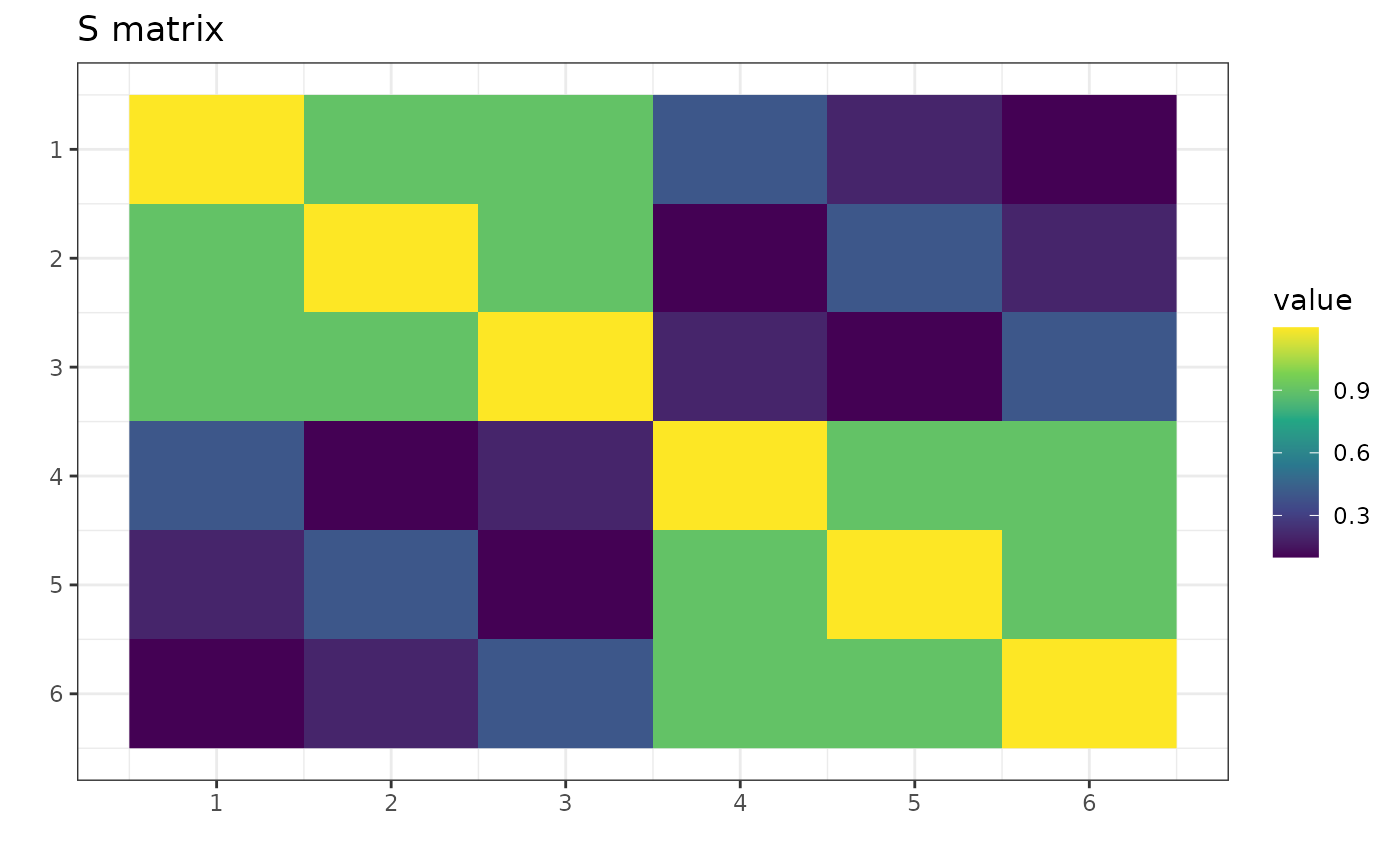
Now, S is a symmetric matrix invariant under the group
.
g_perm <- gips_perm("(1,2,3)(4,5,6)", p)
U_Gamma <- prepare_orthogonal_matrix(g_perm)
block_decomposition <- t(U_Gamma) %*% S %*% U_Gamma
round(block_decomposition, 5)
#> [,1] [,2] [,3] [,4] [,5] [,6]
#> [1,] 3.0 0.7 0.0000 0.0000 0.0000 0.0000
#> [2,] 0.7 3.0 0.0000 0.0000 0.0000 0.0000
#> [3,] 0.0 0.0 0.3000 0.0000 0.2500 0.0866
#> [4,] 0.0 0.0 0.0000 0.3000 -0.0866 0.2500
#> [5,] 0.0 0.0 0.2500 -0.0866 0.3000 0.0000
#> [6,] 0.0 0.0 0.0866 0.2500 0.0000 0.3000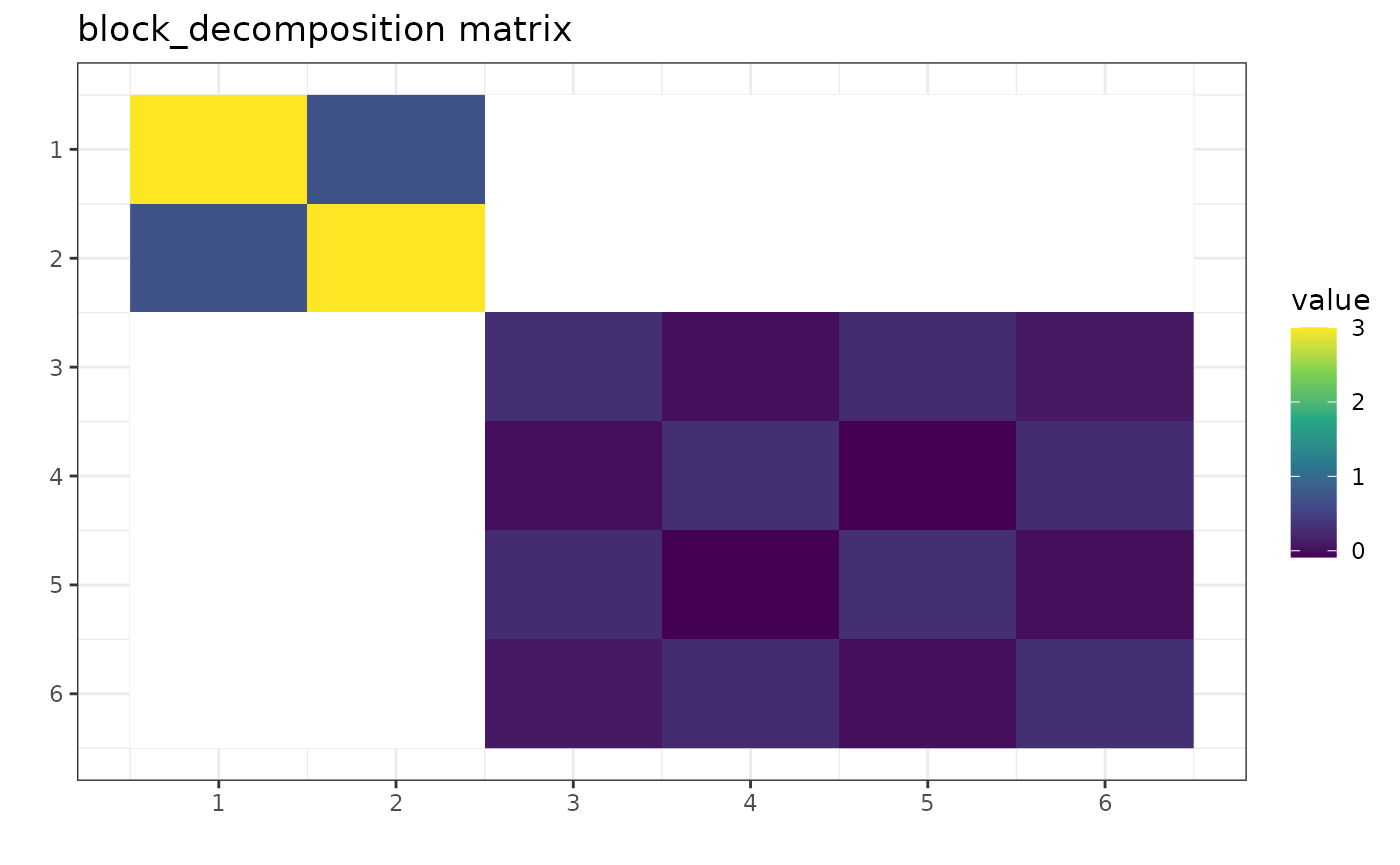
Again, this result is in accordance with [1], Theorem 1. Notice the
zeros in block_decomposition:
Project Matrix - [1, Eq. (6)]
One can also take any symmetric square matrix S and find
the orthogonal projection on
,
the space of matrices invariant under the given permutation:
The projected matrix is the element of the cone , which means:
So it has some identical elements.
Trivial case
Note that for we have .
So, no additional assumptions are made; thus, the standard covariance estimator is the best we can do.
Notation
We will abbreviate the notation: when the is a cyclic group of a permutation , we will write .
Example
Let S be any symmetric square matrix:
round(S, 2)
#> [,1] [,2] [,3] [,4] [,5] [,6]
#> [1,] 137.51 -16.21 10.03 0.16 -24.35 -17.42
#> [2,] -16.21 34.08 -10.62 15.93 12.23 -2.74
#> [3,] 10.03 -10.62 35.47 3.10 -3.81 -9.60
#> [4,] 0.16 15.93 3.10 26.74 7.71 -13.51
#> [5,] -24.35 12.23 -3.81 7.71 26.00 -7.24
#> [6,] -17.42 -2.74 -9.60 -13.51 -7.24 16.77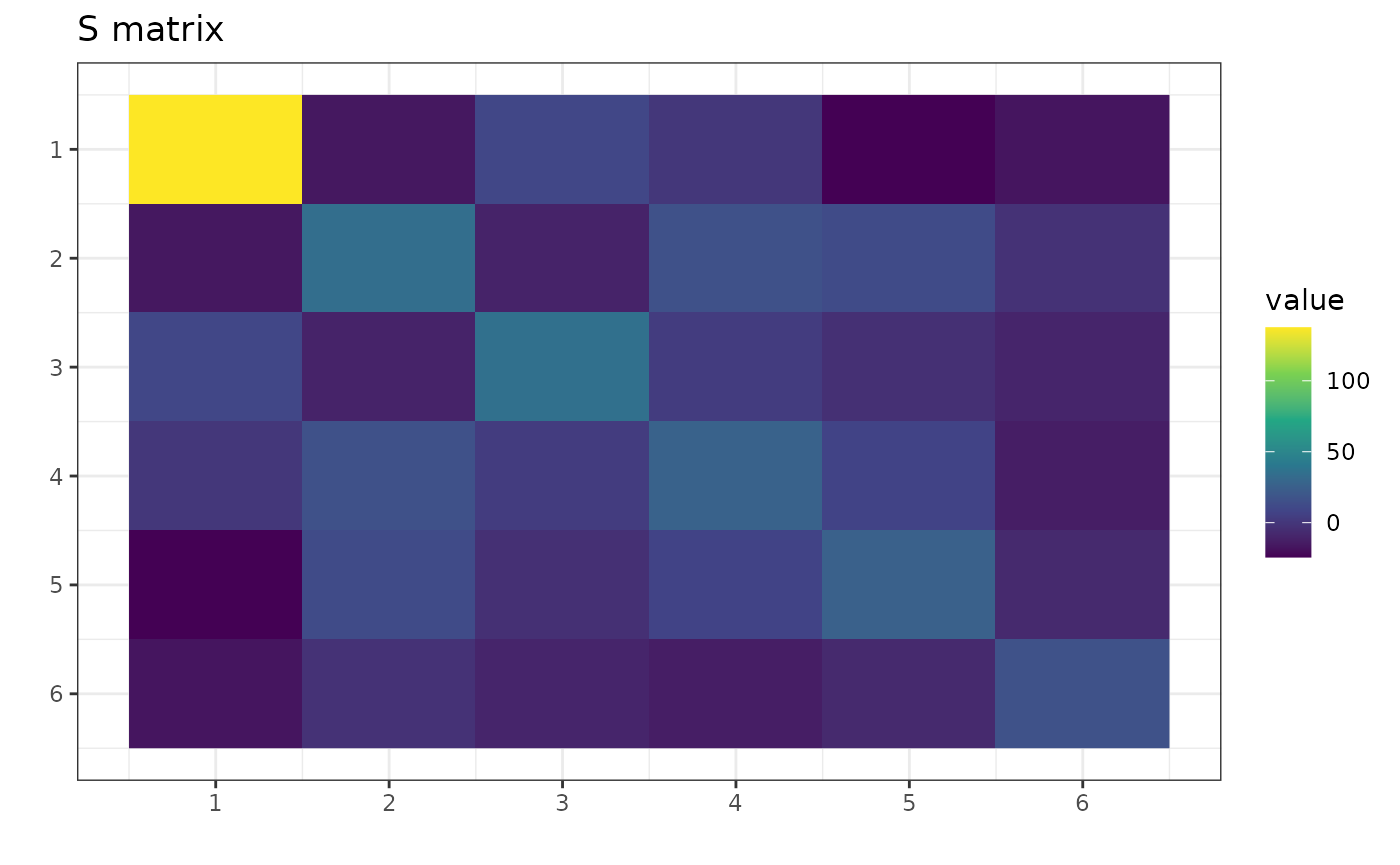
One can project this matrix, for example, on :
S_projected <- project_matrix(S, perm = "(1,2)(3,4,5,6)")
round(S_projected, 2)
#> [,1] [,2] [,3] [,4] [,5] [,6]
#> [1,] 85.80 -16.21 -0.28 -3.91 -0.28 -3.91
#> [2,] -16.21 85.80 -3.91 -0.28 -3.91 -0.28
#> [3,] -0.28 -3.91 26.25 -1.51 -8.66 -1.51
#> [4,] -3.91 -0.28 -1.51 26.25 -1.51 -8.66
#> [5,] -0.28 -3.91 -8.66 -1.51 26.25 -1.51
#> [6,] -3.91 -0.28 -1.51 -8.66 -1.51 26.25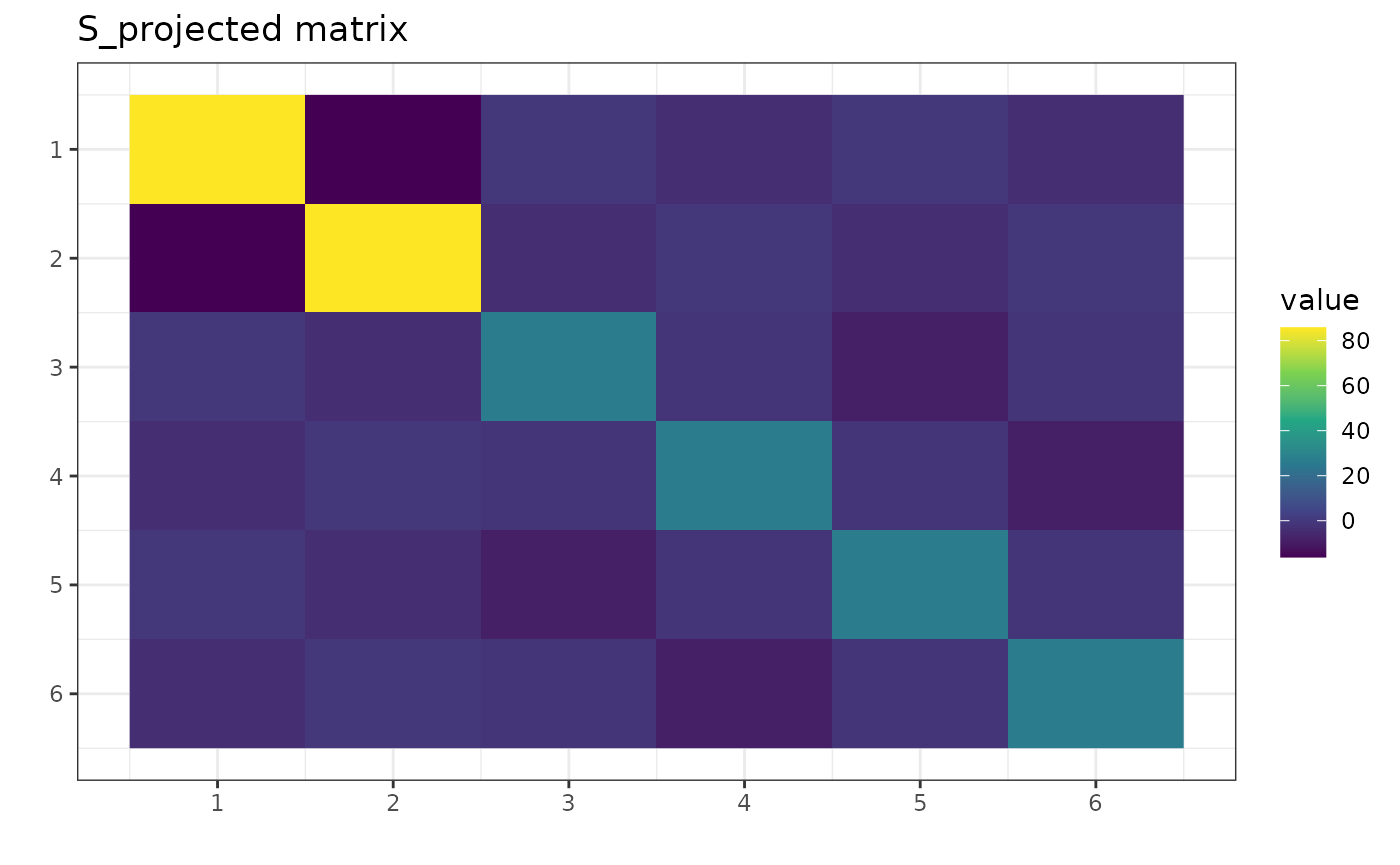
Notice in the S_projected matrix there are identical
elements according to the equation from the beginning of this section.
For example, S_projected[1,1] = S_projected[2,2].
and n0
It is a well-known fact that without additional assumptions, the Maximum Likelihood Estimator (MLE) of the covariance matrix in the Gaussian model exists if and only if . However, if the additional assumption is added as the covariance matrix is invariant under permutation , then the sample size required for the MLE to exist is lower than . It is equal to the number of cycles, denoted hereafter by .
For example, when
and the permutation
is discovered by the find_MAP() function, it consists of a
single cycle, so
.
Therefore a single observation would be enough to estimate a covariance
matrix with project_matrix(). If the permutation
is discovered, then
,
and so 2 observations would be enough.
To get this
number in gips, one can call summary() on the
appropriate gips object:
g1 <- gips(S, n, perm = "(1,2,3,4,5,6)", was_mean_estimated = FALSE)
summary(g1)$n0
#> [1] 1
g2 <- gips(S, n, perm = "(1,2)(3,4,5,6)", was_mean_estimated = FALSE)
summary(g2)$n0
#> [1] 2This is called n0 and not
because it is increased by 1 when the mean was estimated:
Bayesian model selection
Given data matrix Z, we would like to discover any hidden structure of dependencies between features. Luckily, the paper demonstrates a way how to find it.
General workflow
- Choose the prior distribution on and .
- Calculate the posteriori distribution (up to a normalizing constant) by the formula [1], (30).
- Use the Metropolis-Hastings algorithm to find the permutation with the biggest value of the posterior probability .
Details on the prior distribution
The considered prior distribution of and :
- is uniformly distributed on the set of all cyclic subgroups of .
-
given
follows the Diaconis-Ylvisaker conjugate prior distribution with
parameters
(real number,
)
and
(symmetric, positive definite square matrix of the same size as
S), see [1], Sec. 3.4.
Footnote: Actually, for the special case of
,
the parameter
is theoretically correct. In gips, we want this to be
defined for all cyclic groups
,
so we restrict
.
Refer to the [1].
gips technical details
In gips,
is named delta, and
is named D_matrix. By default, they are set to
and diag(d, p), respectively, where
d = mean(diag(S)). However, it is worth running the
procedure for several parameters D_matrix of form
for positive constant
.
Small
(compared to the data) favors small structures. Large
will “forget” the data.
One can calculate the logarithm of formula (30) with the function
log_posteriori_of_gips().
Interpretation
When all assumptions are met, the formula (30) puts a number on each permutation’s cyclic group. The bigger its value, the more likely the data was drawn from that model.
When one finds the permutation group that maximizes (30),
one can reasonably assume the data was drawn from the model
where
In such a case, we call the Maximum A Posteriori (MAP).
Finding the MAP Estimator
The space of all permutations is enormous for bigger (in our experiments, is too big). In such a big space, estimating the MAP is more practical than calculating it exactly.
Metropolis-Hastings algorithm suggested by the authors of [1] is a natural way to do
it. To see the discussion on it and other options available in
gips, see
vignette("Optimizers", package="gips") or its pkgdown
page.
Example
Let’s say we have this data, Z. It has dimension
and only
observations. Let’s assume Z was drawn from the normal
distribution with the mean
.
We want to estimate the covariance matrix:
dim(Z)
#> [1] 4 6
number_of_observations <- nrow(Z) # 4
p <- ncol(Z) # 6
# Calculate the covariance matrix from the data (assume the mean is 0):
S <- (t(Z) %*% Z) / number_of_observations
# Make the gips object out of data:
g <- gips(S, number_of_observations, was_mean_estimated = FALSE)
g_map <- find_MAP(g, optimizer = "brute_force")
#> ================================================================================
print(g_map)
#> The permutation (1,2,3,4,5,6):
#> - was found after 362 posteriori calculations;
#> - is 133.158 times more likely than the () permutation.
S_projected <- project_matrix(S, g_map)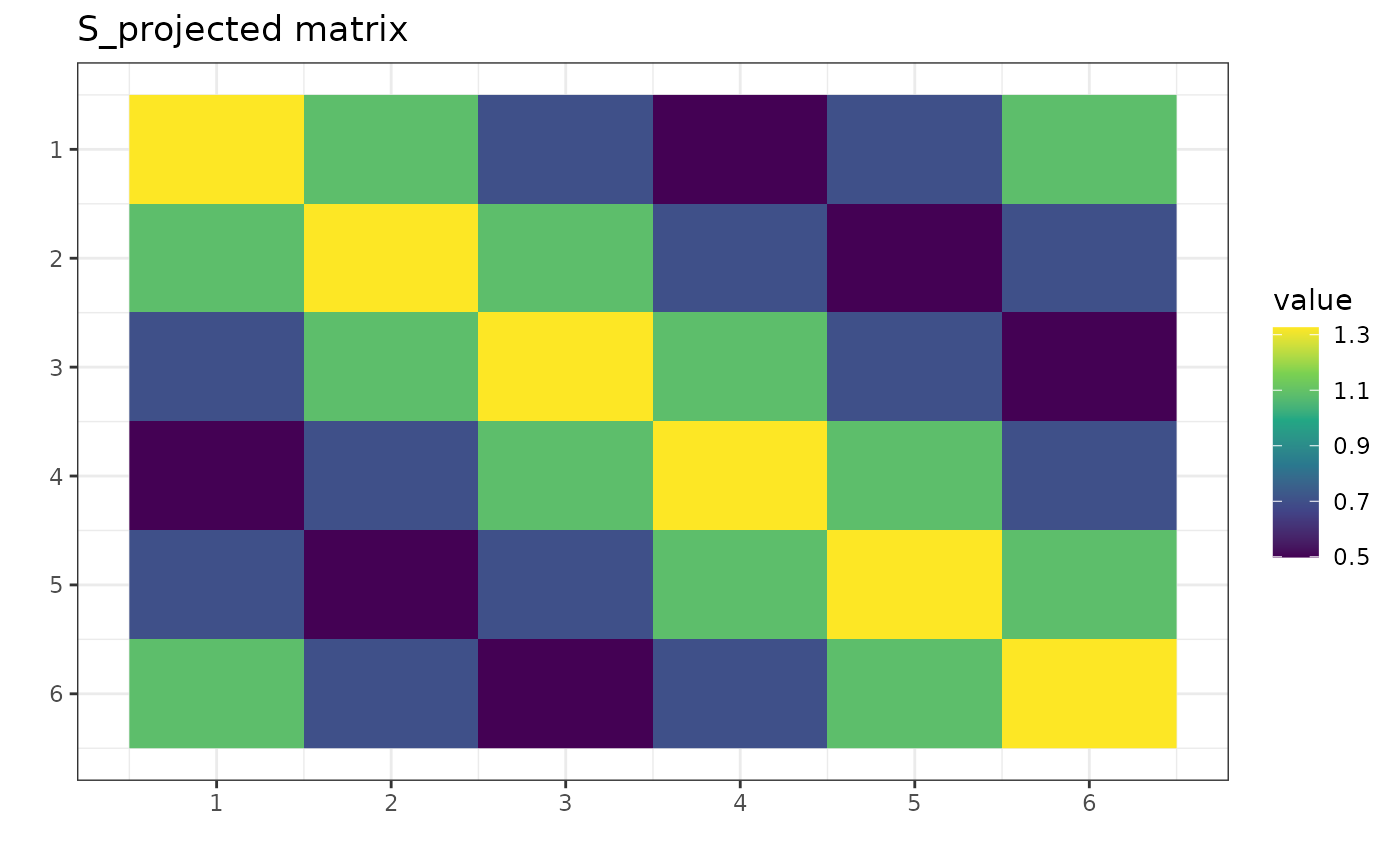
We see the posterior probability [1,(30)] has the biggest
value for the permutation
.
It is 133.16 times bigger than for the trivial
permutation. Under the assumptions (centered Gaussian), we therefore
interpret the model
as more reasonable than
for the data Z.
Information Criterion - AIC and BIC
One may be interested in Akaike’s An Information Criterion (AIC) or Schwarz’s Bayesian Information Criterion (BIC) of the found model. Those are defined based on log-Likelihood:
where .
The MLE of in a model invariant under is . Further, for every we have , so:
which can be calculated by logLik.gips().
Then AIC and BIC are defined by:
A smaller value of the criteria for a given model indicates a better fit.
Those can be calculated by AIC.gips() and
BIC.gips().
Estimated mean
When the mean was estimated, we have , where . Then in the we use in stead of . Definitions of AIC and BIC stay the same.
Example
Consider an example similar to one in the Bayesian model selection section:
Let’s say we have this data, Z. It has dimension
and
observations. Let’s assume Z was drawn from the normal
distribution with the mean
.
We want to estimate the covariance matrix:
dim(Z)
#> [1] 7 6
number_of_observations <- nrow(Z) # 7
p <- ncol(Z) # 6
S <- (t(Z) %*% Z) / number_of_observations
g <- gips(S, number_of_observations, was_mean_estimated = FALSE)
g_map <- find_MAP(g, optimizer = "brute_force")
#> ================================================================================
AIC(g)
#> [1] 64.19906
AIC(g_map) # this is smaller, so this is better
#> [1] 62.99751
BIC(g)
#> [1] 63.06318
BIC(g_map) # this is smaller, so this is better
#> [1] 62.78115We will consider a g_map better model both in terms of
the AIC and the BIC.
References
[1] Piotr Graczyk, Hideyuki Ishi, Bartosz Kołodziejek, Hélène Massam. “Model selection in the space of Gaussian models invariant by symmetry.” The Annals of Statistics, 50(3) 1747-1774 June 2022. arXiv link; DOI: 10.1214/22-AOS2174
[2] “Learning permutation symmetries with gips in R” by
gips developers Adam Chojecki, Paweł Morgen, and Bartosz
Kołodziejek, Journal of
Statistical Software.